吐槽某计算机讲师,对,说的就是讲师。越是没能力,也是B事多。从几个方面来想,因为没能力,所以怕显得自己没能力,各种B事要求学生,自己又没能力提不出有建设性的意见,未完待续
分類: 未分類
-
Anti-AIGC Rewriter 架构重构:内容优先模式
当前系统采用「原位回填」方案:读入 docx → 逐段分类 → 调 LLM 重写 → 把新文本塞回原段 run。这种做法的核心矛盾是既要保全格式又要降 AIGC 率,两件事冲突严重——run 级格式保留约束了改写的自由度,而且 replace_paragraph_text_preserve_runs 在跨 run 长度变化时经常出毛病。
背景与目标
用户新需求明确:放弃细粒度格式保留,转向「内容优先」模式,只保留结构骨架(标题层级 + 参考文献/致谢/声明),正文做强重写,导出全新 docx。
核心设计原则
项目 旧方案 新方案(内容优先) 格式策略 保留 run 级字体/样式 只保留标题层级 + 结尾区块 图题/表题/表注 强保 不再强保,可酌情重写 段内字体 死保每个 run 不保留,整段纯文本 输出方式 原位修改原 docx 导出全新 docx System Prompt 通用型 大幅强化 6 条降 AIGC 规则
架构总览
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐│ file_parser │────▶│ doc_analyzer │────▶│ llm_rewriter │────▶│ doc_builder ││ (解析原文件) │ │ (结构识别) │ │ (强重写引擎) │ │ (构建新docx) │└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
四大模块职责
1. file_parser.py — 文件解析层(保留+微调)
- 已有 txt/docx/pdf 解析
- 新增:
parse_docx_structured()函数,返回结构化段落列表而非纯文本拼接 - 每个段落对象包含:text,
style_name,heading_level(1/2/3/None),is_list_item
2.
doc_analyzer.py— 结构识别器(新建)- 从 llm_service.py 中剥离段落分类逻辑(classify_paragraph_type, is_heading_like_text, is_trigger_match 等)
- 负责将段落列表标记为以下类型之一:
- heading — 一级/二级/三级标题(保留不改)
reference/acknowledgment/declaration— 结尾区块(保留不改)body— 正文(强重写目标)caption— 图题/表题(按新策略可酌情轻改或跳过)
- 输出一个
AnalyzedDocument对象:有序段落列表 + 各段类型标签
3.
llm_rewriter.py— 强重写引擎(从 llm_service.py 重构)- 全新 System Prompt 融入用户的 6 条核心规则:
- 极高文本波动率:长短句交错,绝不排比
- 提升困惑度:禁用「首先、其次」,替换为「不可否认的是、结合实际情况来看」
- 注入生涩感:学术术语准确,模拟本科生毕设口吻
- 核心语义不变:保留数据+论点
- 精准锚定参考文献标号
[1][2] - 绝对禁止废话(零对话模式)
- 附加改写策略(融入 prompt):
- 打破句式对称
- 剔除过渡冗余(「众所周知」「值得注意的是」等)
- 动作实体化(减少主谓宾,多用被动/无主语句)
- 提升专业词汇密度
- 保留:分块 smart_chunking、段内拆分 split_paragraph_into_rewrite_units
- 保留:重试/相似度检测/回退机制(needs_retry, is_too_similar, should_fallback_to_source)
- 删除:replace_paragraph_text_preserve_runs(不再需要 run 级回填)
4.
doc_builder.py— 新文档构建器(新建)- 接收
AnalyzedDocument + 重写结果 - 创建全新
python-docx.Document() - 标题段:根据
heading_level用doc.add_heading(text, level=n)添加 - 正文段:
doc.add_paragraph(rewritten_text)添加重写后的纯文本 - 保留区块(参考文献、致谢等):原样添加
- 可选:设置一个统一的学术论文样式模板(宋体正文 + 黑体标题等)
文件变更清单
[NEW]
doc_analyzer.py- 从 llm_service.py 提取的结构识别逻辑
- 定义
StructuredParagraph和AnalyzedDocument数据类 analyze_document(paragraphs) → AnalyzedDocument
[NEW]
doc_builder.pybuild_document(analyzed_doc, rewrite_results, output_path)→ 生成新 docx
[NEW]
llm_rewriter.py- 全新 System Prompt + 重写策略
rewrite_body_paragraphs(analyzed_doc, client, model, reference_list) → AsyncGenerator流式重写
[MODIFY] llm_service.py
- 大幅瘦身:移除段落分类逻辑(→
doc_analyzer.py)、移除 run 替换逻辑 - process_paper_stream() 重构为编排层,调用上述三个模块
- 保留 API key 工具函数 + generate_paper_stream()
[MODIFY] file_parser.py
- 新增
parse_docx_structured()返回结构化段落对象列表
[MODIFY] main.py
- API 不变,内部调用链路更新
用户审阅事项
IMPORTANT
导出新 docx 意味着原文件的所有图片、嵌入式表格、SmartArt 等非文本元素将不会携带到新文档中。 如果你的论文含有重要的图片/表格,需要在重写完成后手动从原文件复制过来。后续迭代可以考虑自动搬运图片,但本次重构先聚焦文本重写核心。
NOTE
图题和表题(如「图 1 系统架构图」)在新方案中默认跳过不重写、原样保留到新文档。如果你希望对它们也做轻改,可以告诉我。
数据流详解
是否用户上传 docx/txt/pdffile_parser: 解析docx?parse_docx_structured提取段落 + style + heading_levelparse_txt / parse_pdf提取纯文本doc_analyzer: 分类标注AnalyzedDocument每段带类型标签llm_rewriter: 逐段强重写仅处理 body 类型段落流式输出到前端doc_builder: 构建新 docx保存到 outputs/用户下载
System Prompt 设计(核心)
text你是核心学术期刊的特约文字校对专家,执行"学术语域重构与信息密度提升"任务。【绝对规则】1. 极高文本波动率:交替使用极短句(5-10字)和长复句(50字以上), 绝不使用排比结构,刻意打破句式对称。适当增加长句的从句嵌套深度, 模拟人类学者的复杂思考路径。2. 提升困惑度:禁用"首先、其次、再次、最后、一方面/另一方面"等连接词, 替换为"不可否认的是、结合实际情况来看、从另一维度审视、就学理而言"等 低频学术表达。逻辑连贯性应通过上下文语义自然衔接。3. 注入生涩感:术语必须准确,但行文应模仿真实本科生毕设的主观推导口吻, 带有轻微的"正在探索"感。将口语化表达转为规范学术概念 (例:把它分成几块 → 进行模块化解耦;效果更好 → 显著优化了某某指标)。4. 核心语义不变:保留所有关键数据、论点、实验结果。不得新增观点。5. 精准锚定参考文献:原文标号([1],[2]等)必须精准转移到重写后 对应论点的末尾,不得遗漏、不得错位。6. 零废话输出模式:直接输出重写后的正文。绝不允许包含任何解释性、 确认性或过渡性文字。【附加策略】- 剔除过渡冗余:删除"众所周知""在此大环境下""值得注意的是"等无意义连词。- 动作实体化:减少"我们设计了…"主谓宾结构,多用无主语句或被动语态 (例:我们使用了Jieba分词 → 研究引入Jieba分词引擎)。- 提升专业词汇密度:确保每段至少有2-3个精确的专业术语或方法名。【边界意识】标题、目录、文献引用项、致谢、声明类文本,不改写,原样返回。
验证计划
自动化测试
- 现有测试:
python -m pytest tests/test_llm_service.py -v(验证 split_paragraph_into_rewrite_units 回归) - 新增单测:
tests/test_doc_analyzer.py— 测试段落分类准确性(标题/正文/参考文献/图题)tests/test_doc_builder.py— 测试从 AnalyzedDocument 构建 docx 的结构正确性
手动验证
- 启动服务
bash start.sh - 在浏览器中上传一个包含标题、正文、参考文献的
.docx测试文件 - 点击重写,观察:
- 流式输出是否正常
- 标题是否被跳过(不被重写)
- 参考文献区块是否被保留
- 下载的新 docx 是否包含正确的标题层级
- 打开下载的 docx 检查格式结构
-
注意事项
任何辅导机构都不能百分百的完全替代你 ,该是你做的,你肯定还得做。比如熟悉文章结构,知道大体有啥。包括最起码的格式,以及你的个人信息是否全面。
你自己检查的点有:
- 个人信息
- 对着模版或者要求文件扫一遍,任何代写或者代做也会有疏漏,唯一不混弄的只有自己。而且现在陷入一个囚徒困境。很多工作室或者团队低价把人招揽进来,要么后期加价,要么做出来很水的东西。
- 切记,在项目没结束的时候不要付尾款。
- 另外,有话提前说,很多sb学校,话不到最后一刻不说,总是最后一刻才说,不给人留修改时间
-
从《王志安》困局——反思现今互联网

为众人抱薪者,不可使其冻毙于风雪。首先从中,我们能看到王局是个人 ,活生生的人 。能看到中年大叔的说教,也有大叔作为记者的直言不讳。他也有作为男人的 事,比如换老婆等等,私生活不应 掺合其他事件分析 ,就事论事。上面youtube视频 解析了为何王局 被针对,从中可以反思出:
做自媒体,无论在哪里,都要有风险意识,出了问题要 有公关,如果不公关,沉默虽然 可以不进入 对方的节奏,可以会处于一种默认的局面 。舆论预判,什么能说 ,在什么时候说,不能因为你是调查记者,就啥都说,这句话也是写给自己的,自勉。“在陌生的战场上,侦查永远在进攻之前”。
-
每晚(经常)写reflection
之前在学校,每天醒来总是拖着疲倦的身体,昏昏沉沉的,即使这几天也没产出什么。总是一种感觉自己很疲惫,总是没按照自己想要的方式度过。总是过度焦虑没有意义,或者说不重要的事。当白天的情绪,没有消解(整理清楚),把困扰和困惑带入到了睡梦中,半夜就会醒来,或者说没有把情绪消化好,带入到了潜意识。写reflection,是重启人生(洗澡也是)。
- 我今天是什么样的心情
- 我为什么会感觉到这样的心情(追问自己,把说不清的感性,变成一种理性)
很多时候,我们发生生命的痕迹,不只是通过照片,因为照片是相对表面的,相对感性,看到的是一个感性的自己。写故事,是抽象的自己。看像是写一个自己或者他人故事,实际是写抽象的自己,自己愤怒,欲望,爱而不得。投入到故事当中,你再看这个故事,有个新的理解。
思辨(考)的前提是勇气。有勇气问出那个别人不敢问的问题。每当我想要做一个事,无论是创业做学术还是什么,冥冥中有个声音你再告诉自己,你读了很多书了吗?思考要有合法性,你没有读很多书,那你没有资格思考这个东西,你没有达到这个学历思考这个东西等等,给自己加上了自己审判(大陆长大的孩子)。先去写,知道自己的进步是有过程的。
当你意识到这个问题,就是问题的开始。
真实的分辨:
- 我的情绪是什么
- 我的欲望是什么
- 我的思考是什么
- 什么是别人想让我做的
- 什么是别人想让我感觉到的
将内在权威和真实感受分离。
发表书/观点的时候,就接受自己被卖,毕竟在这种二元对立的舆论环境。
-
tools——自动分析视频内容
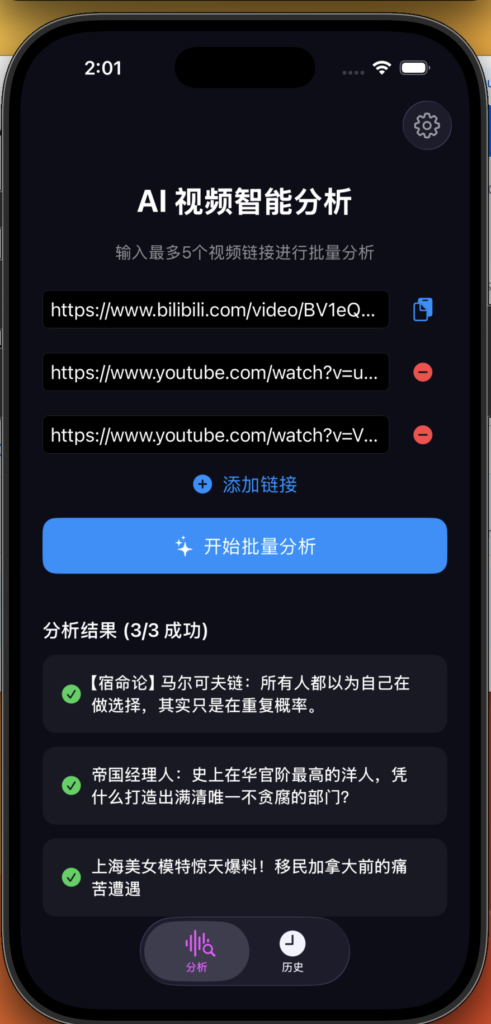
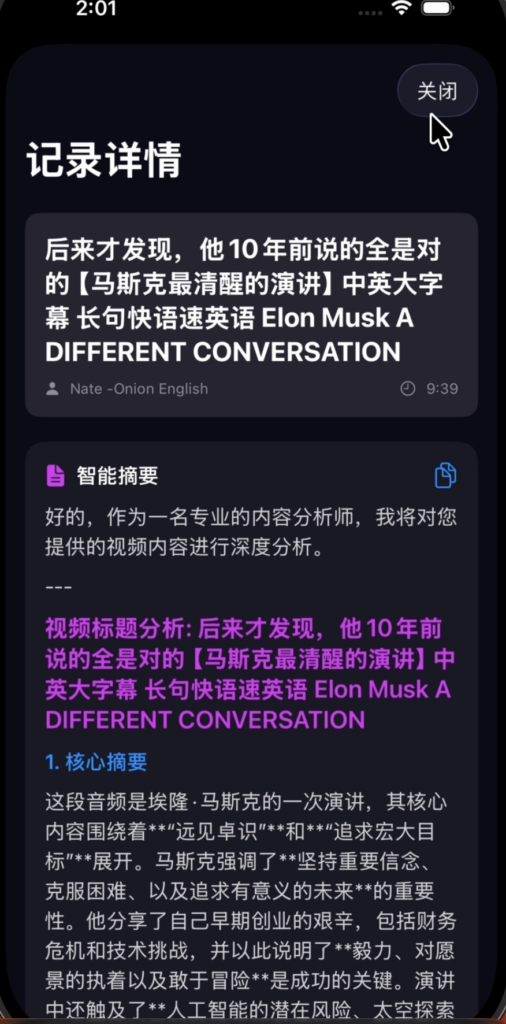
灵感来自百度网盘的ai看功能。大概率以后ai看功能都是付费的,youtube的视频直接一个链接给gemini,他会自动给你分析,b站的就不行。在ai时代,很多自媒体博主写的就是屎,没必要都看完,知道他大概就行,如果觉得有营养,再细看,珍惜时间就是珍惜生命。笔者,手搓一个ios应用(巨魔安装),后端放在Google cloud,详细开源在github:https://github.com/ityongsheng/VideoAnalysis
-
把话说完
不怕修改,就怕挤牙膏,一次性不把话说完。因为每次修改,无论AI还是人工,需要需要回忆之前做了啥,(AI会加载上下文,也就是token,也就是更多成本)。而且,🧑💻我的电脑硬盘已经很大了,跑着这么多程序,一两个月会清理缓存或者数据,毕竟大家都有自己隐私,我长时间保存也不好(嫌占内存)。发完后,先缓存,先备份,需要修改的时候,等问清楚,一次性做好,而且这样质量还高。重复性多次修改,也容易做出屎山。